Reinforcement Learning from Human Feedback, InstructGPT, and ChatGPT

Note: some parts of this blog post are generated by ChatGPT! :)
Welcome to my blog post on ChatGPT! In this post, we will dive into the inner workings of ChatGPT and how it is trained. However, before we get into the specifics of ChatGPT, it’s important to first review some relevant prior works and concepts to give us a strong foundation. Once we have a solid understanding of these foundations, we can move on to exploring ChatGPT in depth.
Let’s get started.
Learning to Summarize From Human Feedback
This work demonstrates the feasibility of significantly improving summary quality through the training of a model that optimizes for human preferences. The authors collect a large dataset of human-generated comparisons between summaries, train a model to predict the summary preferred by humans, and use this model as a reward function to fine-tune a summarization policy using reinforcement learning. They showed that training with human feedback significantly outperforms strong baselines in English summarization, and also human feedback models have better generalization to new domains than supervised models.
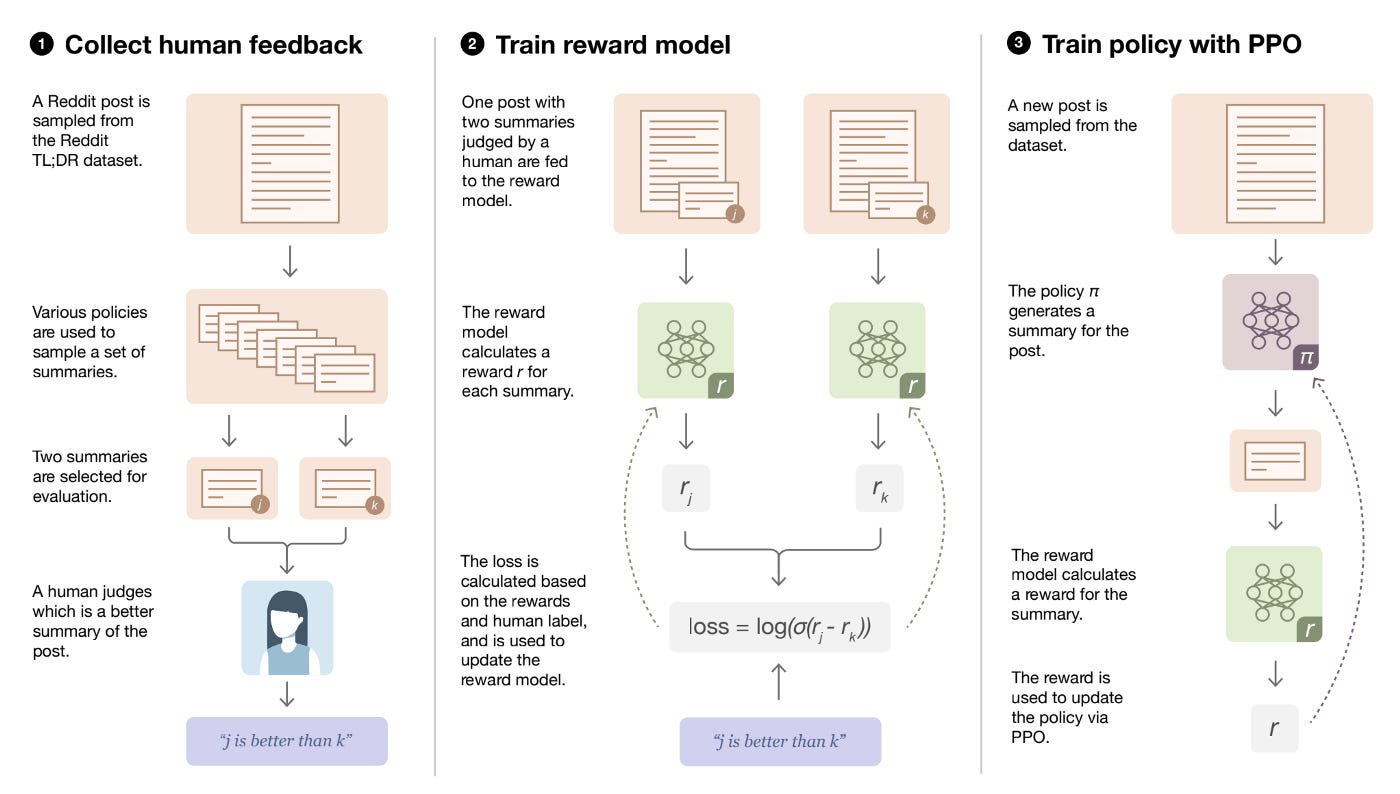
They use a Reddit posts dataset and propose three steps as follows in the paper:
For a Reddit post from the dataset, they sample summaries from several sources including the current policy, initial policy, original reference summaries, and various baselines. Humans are asked to choose the best summary for a given Reddit post from a batch of pairs of summaries. The labeler needs to provide feedback for a pair of summaries j, k like “j is better than k”.
Then they train a reward model using human comparisons. Given a post and two summaries judged by a labeler, the loss function is calculated based on the predicted reward r by the model for each summary, and also the human labels. Then the reward model is updated using the calculated loss. The reward model is a pre-trained model which is fine-tuned using supervised learning, with a randomly initialized linear head that outputs a scalar value. Then they train this model to predict which summary y ∈ {y0, y1} is better as judged by a human, given a post x. If the summary preferred by the human is yi, the loss for reward model can be written as:
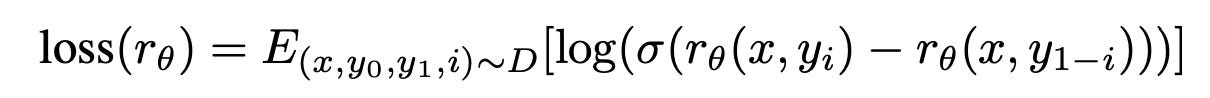
where rθ(x, y) is the scalar output of the reward model for post x and summary y with parameters θ, and D is the dataset of human judgments. In addition, they add a KL divergence term in the reward. This KL term serves two purposes. First, it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode. Second, it ensures the policy doesn’t learn to produce outputs that are too different from those that the reward model has seen during training.
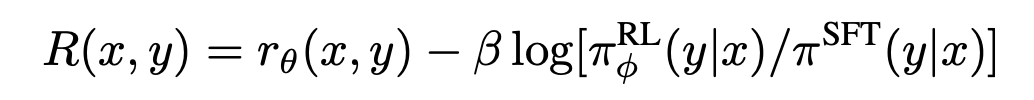
Then, they optimize the policy using the reward model as a guide. The logit output of the reward model is treated as a reward to be optimized using the PPO algorithm and reinforcement learning. The PPO policy is initialized by a model fine-tuned on the Reddit TL;DR dataset using supervised learning. For the PPO value function, they use a Transformer with completely separate parameters from the policy. They initialize the value function to the parameters of the reward model. In their experiments, the reward model, policy, and value function are the same size.
InstructGPT: Training language models to follow instructions with human feedback
This paper presents a method for aligning language models with user intent on a variety of tasks through fine-tuning with human feedback. Starting with labeler-written and API-submitted prompts, a dataset of labeler demonstrations of desired model behavior is collected and used to fine-tune GPT-3 through supervised learning. A dataset of rankings of model outputs is then collected and used to further fine-tune the supervised model with reinforcement learning and human feedback, resulting in the development of InstructGPT models. These models demonstrate improvements in truthfulness and reductions in toxic output generation while maintaining minimal performance regressions on public NLP datasets.
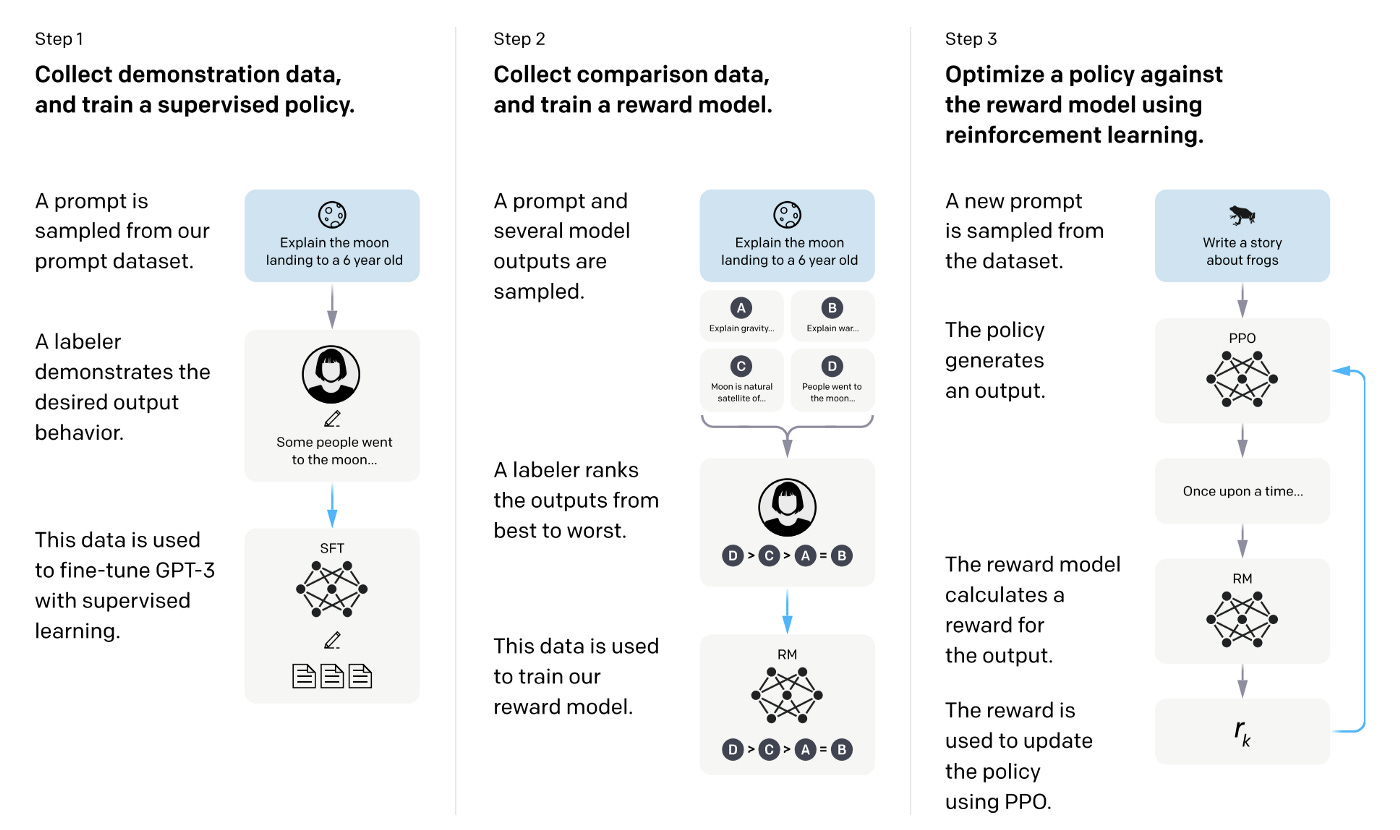
To create the initial InstructGPT models, labelers were asked to write prompts themselves. This was necessary because instruction-like prompts were not frequently submitted to regular GPT-3 models on the API, and were needed to begin the process. Three types of prompts were requested: plain prompts where labelers were asked to come up with an arbitrary task with sufficient diversity, few-shot prompts consisting of an instruction and multiple query/response pairs, and user-based prompts based on use cases from API waitlist applications (they had a number of use-cases stated in waitlist applications to the OpenAI API). These prompts were used to produce three datasets for fine-tuning: one with labeler demonstrations for training SFT (Supervised fine-tuning) models, one with labeler rankings of model outputs for training RMs (Reward Models), and one without human labels for RLHF (Reinforcement Learning from Human Feedback) fine-tuning. In addition, another source of data is used: a dataset of prompts submitted to early InstructGPT models on the API. These two sources of prompts cover a wide range of tasks, including generation, question answering, dialog, summarization, extractions, and other natural language tasks.
Here is a screenshot of the web interface they used for human labels:
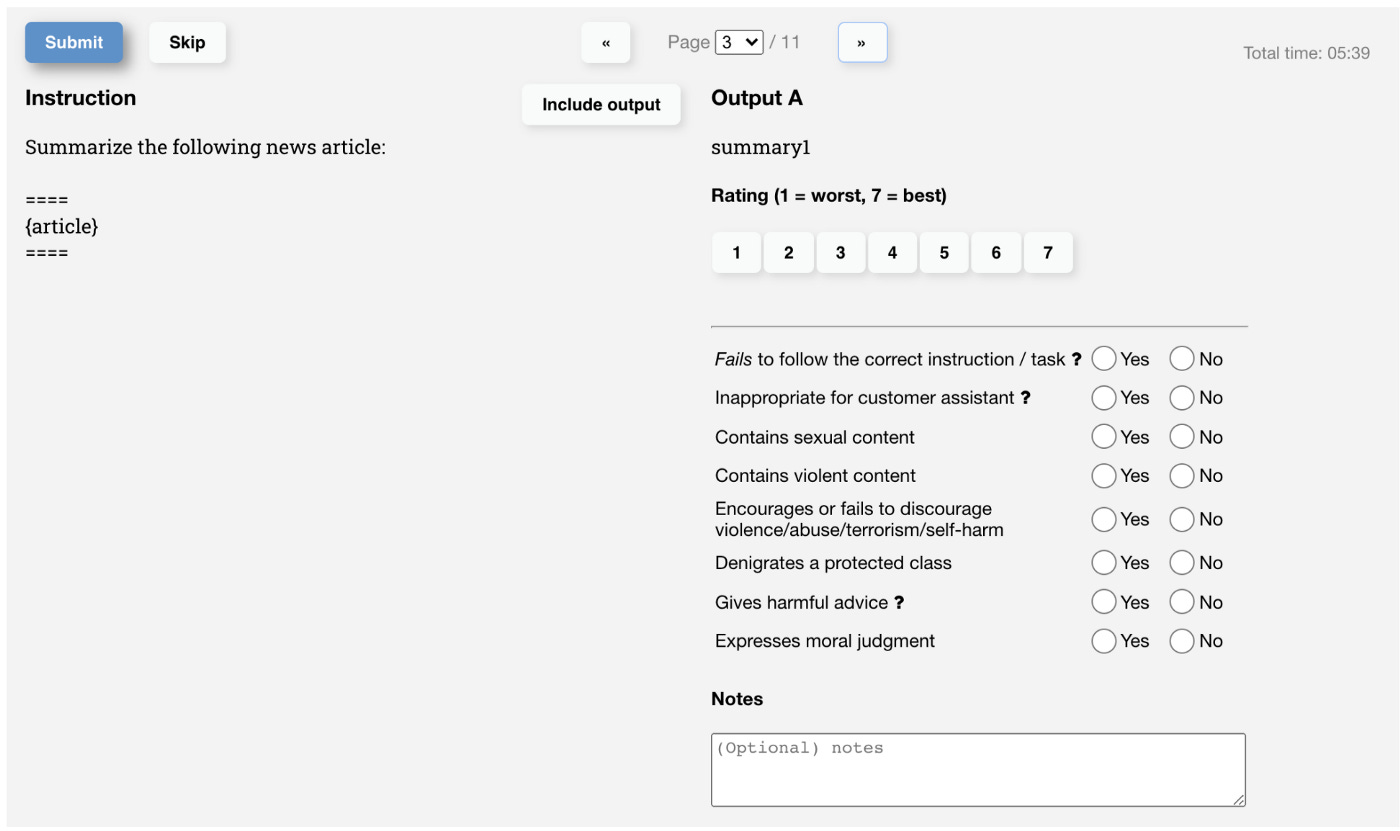
Here are the steps to train InstructGPT.
First, the authors collect demonstration data and use it to train a supervised policy. The demonstration data consists of desired behavior on a specific input prompt distribution, and is provided by labelers. A pre-trained GPT-3 model is then fine-tuned on this data using supervised learning to have the SFT model.
The authors also collect comparison data, in which labelers indicate their preferred output for a given input. This data is used to train a reward model that predicts the output preferred by humans. Starting from the SFT model with the final unembedding layer removed, they trained a model to take in a prompt and response, and output a scalar reward. In this paper, the authors present labelers with a range of
Kresponses (from 4 to 9) to rank, instead of just presenting a pair of summaries to compare as in previous research. This results inC(K,2)comparisons for each prompt shown to a labeler. To prevent overfitting and improve efficiency, the authors chose to train on allC(K,2)comparisons from each prompt as a single batch element, rather than shuffling the comparisons into a single dataset and training on them one at a time. This approach is more computationally efficient because it only requires a single forward pass of the reward model for each completion, rather thanC(K,2)forward passes. Additionally, this method achieved improved validation accuracy and log loss compared to the previous approach. The loss function for RM training is as follows:
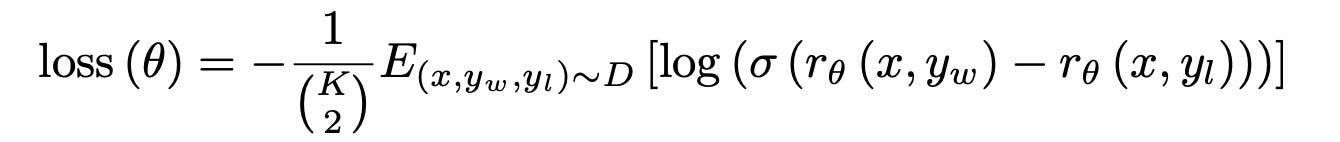
where rθ(x, y) is the scalar output of the reward model for prompt x and completion y with parameters θ, yw is the preferred completion out of the pair of yw and yl, and D is the dataset of human comparisons.
To further optimize the supervised policy SFT, the authors use the output of the reward model as a scalar reward and fine-tune the policy to optimize this reward using the Proximal Policy Optimization (PPO) algorithm. The objective for RL training is as follows:
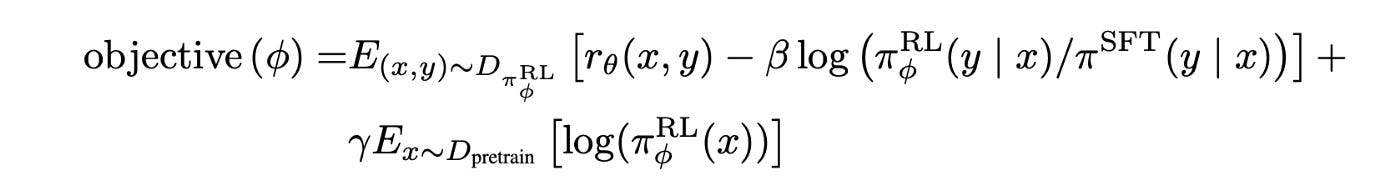
You can refer to the paper for more details.
ChatGPT
ChatGPT is a variant of GPT (Generative Pre-training Transformer), which is a transformer-based language model that was trained to generate human-like text. It is fine-tuned from a model in the GPT-3.5 series and on a large dataset of internet text and can generate coherent and coherent paragraphs of text that are difficult to distinguish from text written by humans.
The architecture of GPT consists of an encoder and a decoder, both of which are made up of a stack of transformer blocks. The encoder processes the input text and converts it into a representation that the decoder can use to generate the output text. The decoder then generates the output text one word at a time, using the representation generated by the encoder and its own internal state to decide what the next word should be.
There is not that much new in ChatGPT compared to the previously explained papers in this post. But let’s see what is happening in the different steps of ChatGPT.
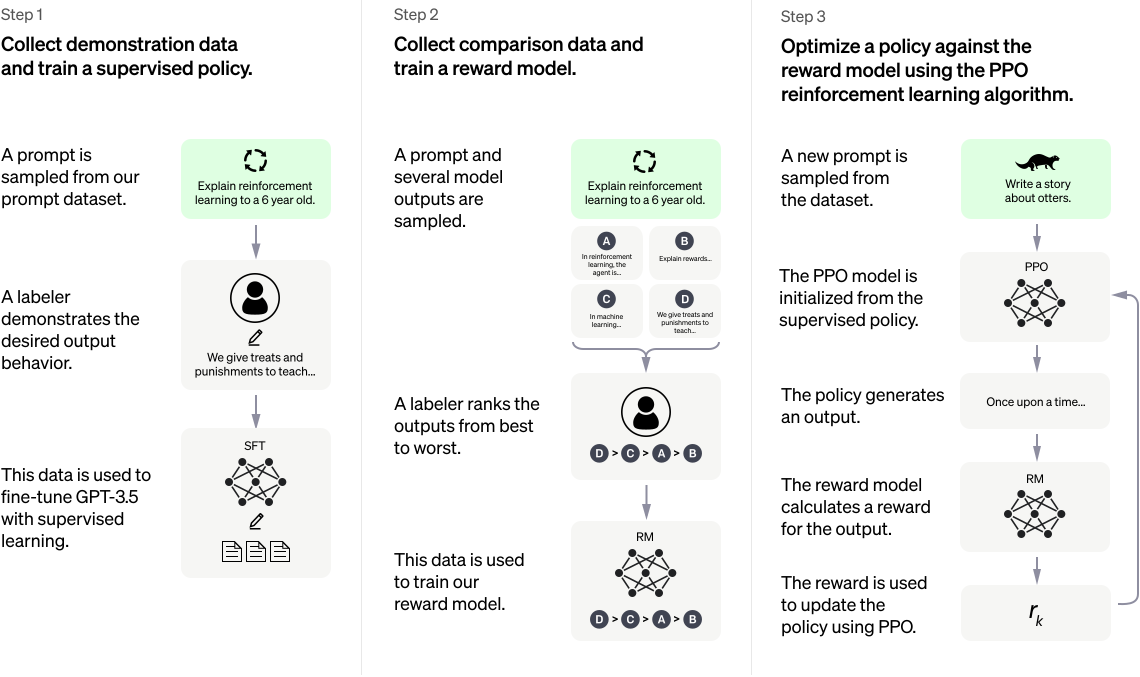
Step 1 — Collect Demonstration Data and Train a Supervised Policy
A labeler samples a prompt from an available dataset and generates a desired behavior and output for that prompt. Then a pre-trained GPT-3.5 model is finetuned on the generated data, resulting in a fine-tuned, supervised model that can follow user instructions. This fine-tuned model is called the SFT (Supervised fine-tuning on human demonstrations) model.
Step 2 — Collect Comparison Data and Train a Reward Model
A user prompt is fed into the SFT model to generate several outputs for the same prompt. Then a user will assign rewards to those generated outputs and rank them which shows the quality of the responses. Then this data will be used to train a reward model. The reward model will get the user prompt and one response and outputs the reward value proportional to the prompt.
Step 3 — Optimize a Policy Against the Reward Model Using the PPO Reinforcement Learning Algorithm
A prompt is sampled from the dataset and is passed to the supervised fine-tuned (SFT) model from step 1, which is used as the policy in a PPO reinforcement learning algorithm, to generate a response. The response is then passed through the reward model from step 2 to assess its quality, and this value is used to further fine-tune the fine-tuning model to better understand human values such as non-toxicity and factuality. This fine-tuning and policy-updating step is done using the PPO algorithm.
In conclusion, ChatGPT is an innovative and powerful language model that has the ability to generate human-like text in real-time conversation. It has the ability to understand and respond to natural language input, making it a valuable tool for a variety of applications such as customer service, language translation, and even creative writing. While it is still in the early stages of development and has limitations, ChatGPT shows great potential for improving and enhancing human-machine communication. Overall, ChatGPT is an exciting advancement in the field of natural language processing and it will be interesting to see how it continues to evolve and be utilized in the future.
It's interesting how you framed the RLHF part. Really appreciate the deep dive into human feedback; it makes you think how critcal the initial policy choice is for these models.